Executive Overview
The speed at which artificial intelligence has moved from research laboratories to the core of organizational operations has been staggering. Within months, we've seen generative AI systems deployed in healthcare diagnostics, financial services, critical infrastructure management, and countless enterprise operations. Yet for all the excitement about AI's transformative potential, security practitioners face an urgent question: How do we secure systems whose behavior we don't fully understand?
In December 2025, the National Institute of Standards and Technology (NIST) released a preliminary draft that attempts to answer this question comprehensively. The Cybersecurity Framework Profile for Artificial Intelligence—or the Cyber AI Profile—represents the first serious attempt at creating a structured, systematic approach to managing the unique cybersecurity challenges and opportunities that AI introduces to organizations.
This is not a generic framework stretched to fit AI. Instead, it acknowledges something fundamental: AI systems operate differently from traditional enterprise systems. They are opaque in ways conventional software isn't. They behave dynamically based on learned patterns rather than deterministic code. They create novel attack surfaces that security teams have never had to defend. And crucially, they offer defensive capabilities we've never had before.
This technical blog examines the Cyber AI Profile in depth, exploring its three interconnected Focus Areas, architectural patterns for implementation, real-world workflows, and the critical decisions organizations must make as they integrate AI securely into operations.
1. Why AI Security Is Fundamentally Different
1.1 The Challenge of Opacity and Emergence
Traditional cybersecurity frameworks were architected for deterministic systems where behavior is predictable and vulnerabilities can be systematically identified and remediated. In that paradigm, you discover a vulnerability, apply a patch, and the problem resolves. Security becomes a matter of identifying and fixing discrete flaws.
AI systems introduce a qualitatively different challenge. When you train a machine learning model on millions of data points, the resulting system learns statistical patterns that may not be explicitly articulated or understood. You cannot open it like source code and trace execution paths. When something goes wrong—when a model behaves unexpectedly or gets manipulated by an attacker—the root cause often remains opaque.
Furthermore, AI systems exhibit emergent behavior. A model trained on one data distribution does not necessarily perform as expected when encountering novel data in production environments. Model accuracy can degrade over time—a phenomenon known as model drift—as real-world conditions diverge from training assumptions. Attackers have learned to exploit this through adversarial examples: carefully crafted inputs with imperceptible perturbations that cause models to misclassify with high confidence, despite appearing normal to humans.
Consider a concrete example: a traffic recognition system trained to identify stop signs. An attacker overlays subtle pixel patterns on a stop sign. These modifications are so minor that any human observer still clearly sees a stop sign. Yet the same ML model that previously recognized it as a stop sign now confidently classifies it as a speed limit sign. This is not a programming bug. It represents a fundamental property of how these systems make decisions based on high-dimensional mathematical spaces.
1.2 The Data Provenance Crisis
The foundation of any AI system is its training data. Compromise that foundation, and everything built on top becomes suspect. Yet managing data security at scale in the ML context presents novel challenges that traditional data governance frameworks were not designed to address.
Attackers have discovered data poisoning—introducing malicious examples designed to make models behave incorrectly. Two attack vectors exist: availability attacks degrade overall model accuracy, causing the system to perform poorly for all users. Integrity attacks, or backdoor attacks, are more sophisticated. They embed hidden triggers that only activate specific incorrect behaviors under certain conditions, making them nearly undetectable through standard validation procedures.
The insidiousness of this threat lies in detection difficulty. A poisoned dataset can appear statistically normal. Poisoned examples might comprise only 1-2% of the training data, making them invisible to casual inspection. A researcher might unknowingly fine-tune a popular open-source model using poisoned data or data containing malicious instructions, creating compromised models that get distributed widely. By the time anyone realizes the compromise, countless downstream systems depend on that corrupted foundation.
Organizations cannot simply patch this threat. Instead, they require comprehensive data provenance tracking—maintaining detailed audit trails for every piece of training data, including source origin, collection timestamps, preprocessing steps, validation results, and weighting decisions in training. Without this capability, forensic investigation after a security incident becomes nearly impossible.
1.3 The Supply Chain Problem
Few organizations build AI models entirely from scratch. Most download pre-trained models from public repositories. They fine-tune models from third parties. They integrate APIs and services from other companies. Each integration point creates supply chain risk.
What if the model you downloaded has been compromised at its source? What if a dependency in your ML pipeline has been silently modified? What if the data you use for fine-tuning was poisoned upstream? These are not hypothetical scenarios. The machine learning supply chain remains young enough that security practices are still developing in many organizations.
The ML supply chain risk encompasses several dimensions. Model integrity issues arise when pre-trained models are not cryptographically signed or verified. Framework vulnerabilities appear in the underlying libraries upon which models depend. Infrastructure compromises could silently poison model training across many organizations. Data source contamination introduces malicious information before it reaches your organization. The complexity of the supply chain makes comprehensive risk management genuinely difficult.
2. The Three Pillars: NIST's Organizational Framework
Rather than creating a monolithic framework that addresses all AI security considerations simultaneously, NIST identified three distinct but interconnected Focus Areas. Each addresses a different dimension of the AI-cybersecurity challenge. Together, they form a comprehensive approach.
Figure 1: NIST Cyber AI Profile - Three Interconnected Focus Areas and Their Relationships

2.1 Focus Area 1: Secure—Protecting AI System Components
The Secure Focus Area addresses a fundamental challenge: integrating AI systems into organizational ecosystems while managing novel, expanded, and altered attack surfaces. This encompasses not just the models themselves, but the entire AI supply chain—training data, ML infrastructure, model registries, and systems that AI components interact with.
When we discuss "securing AI," we address a multi-layered attack surface. Let's examine each layer in detail.
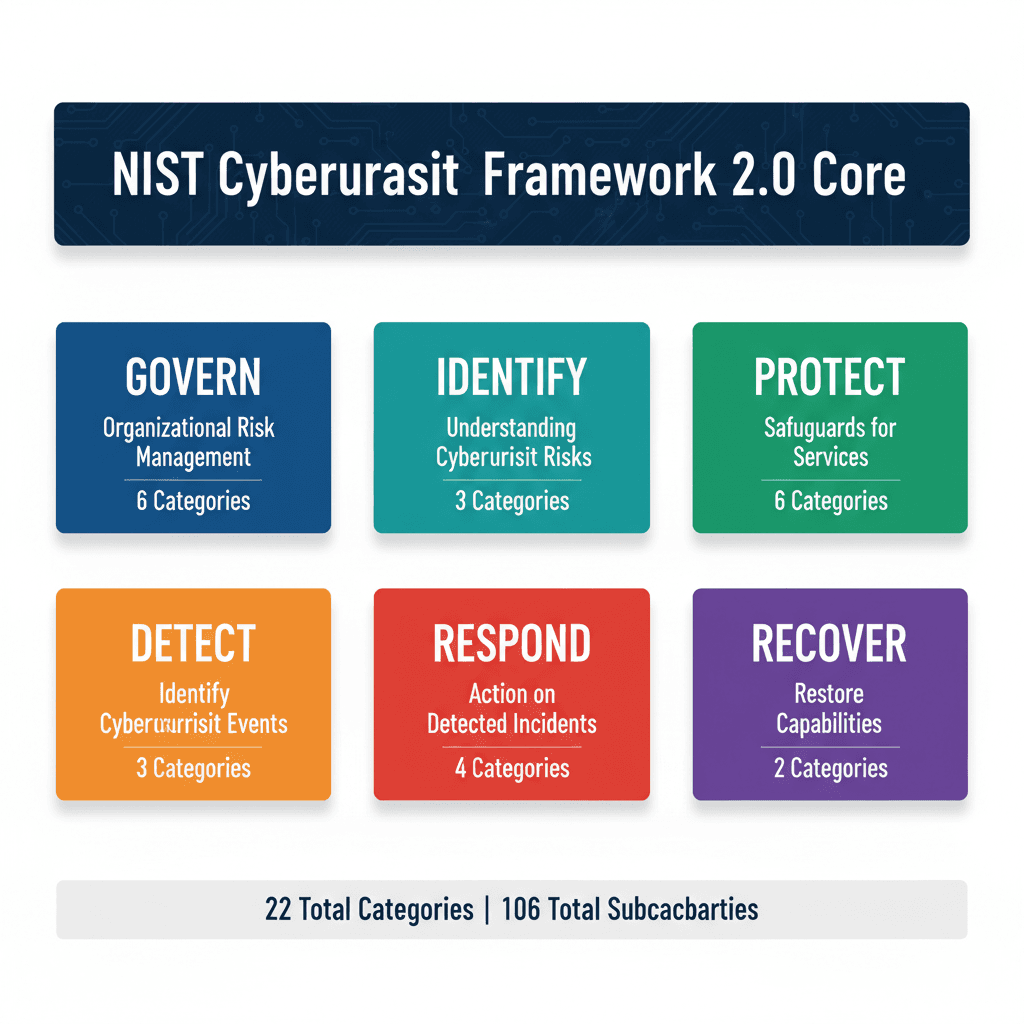
Figure 2: AI Attack Surface - Four-Layer Threat Taxonomy
The Data Layer (Foundation)
The data layer represents the foundation upon which the entire AI system rests. Attack this layer, and you compromise everything built above it.
Data poisoning attacks take different forms depending on attacker objectives. Availability attacks introduce noise that degrades overall model accuracy. An attacker might mix data contradicting legitimate patterns, making the model less accurate for everyone. Integrity attacks are more targeted. An attacker embeds specific triggers—conceptually similar to hidden passwords—that cause the model to misbehave only when presented with inputs containing those triggers.
Consider a concrete example: a bank deploys an AI system to approve loans. An attacker could poison training data such that any loan application containing a specific pattern in the applicant's name receives automatic approval, while the system behaves normally for everyone else. This attack might remain undetected until forensic analysis specifically looks for such patterns.
The challenge of detection cannot be overstated. A poisoned dataset can pass statistical normalcy checks. Poisoned examples might comprise only 1-2% of training data, making them nearly impossible to identify through casual inspection. Once training completes, discovering hidden backdoors requires sophisticated analysis potentially spanning thousands or millions of data points.
This reality necessitates data provenance tracking: maintaining detailed records for every piece of data including origin, collection date, preprocessing steps, validation results, and training weights. This is not optional for organizations with security-critical AI systems.
Validate data provenance and integrity before ingestion
Scan for poisoning attempts using anomaly detection
Implement data sanitization and filtering
Maintain versioned datasets with cryptographic hashes
The Model Layer
The model layer encompasses the mathematical structure that has learned patterns from training data. This layer has vulnerabilities specific to AI systems.
Adversarial examples represent one attack class. Attackers craft inputs designed to fool models into making incorrect predictions. The perturbations can be so subtle that humans notice nothing, yet the model's confidence in its incorrect prediction remains high. In computer vision contexts, this might involve adding imperceptible noise to an image. In NLP contexts, attackers might add synonyms or rephrase sentences while preserving semantic meaning but changing model behavior.
Model inversion attacks allow attackers to reconstruct sensitive information from training data through carefully constructed model queries. By systematically probing a model's outputs, attackers can extract personally identifiable information (PII) or protected health information (PHI). This represents data theft without direct database access.
Model extraction attacks enable attackers to create functional replicas of your model through repeated queries and output observation. This serves attackers in two ways: they can experiment and discover vulnerabilities without alerting your security team, and they potentially compromise your intellectual property.
Large language models introduce additional attack surface through prompt injection. Attackers embed hidden instructions in seemingly innocent input—perhaps in web content visited by someone using an LLM, or in documents uploaded to a system. Those hidden instructions get processed alongside the user's legitimate query, potentially causing the model to override its intended behavior or leak information.
Finally, model drift creates security implications. Over time, as real-world conditions change, the statistical distribution of data your model encounters diverges from training distributions. Model accuracy degrades. From a security perspective, models can start missing threats or anomalies they were previously trained to detect.
Implement model versioning and cryptographic signing
Monitor model performance metrics for unexpected degradation
Conduct adversarial testing before deployment
Implement access controls for model storage and deployment
The Application and Infrastructure Layers
At the application layer, AI systems integrate with broader organizational infrastructure. These integration points create vulnerabilities. API manipulation attacks, privilege escalation opportunities, and tool misuse by AI agents all become relevant threats.
If an AI system has access to certain databases or APIs for legitimate analysis, attackers might trick it into misusing that access. An AI agent given legitimate access to specific databases might, through careful prompting, be manipulated into querying restricted databases or exfiltrating sensitive information.
The infrastructure layer encompasses compute resources, storage systems, and pipelines that train and serve models. Supply chain compromises pose real threats. A compromised ML framework or malicious dependency update could silently poison model training across many organizations. Insecure model storage—lacking access controls, encryption, or integrity verification—creates opportunities for attackers to tamper with deployed models.
Establish supply chain security practices for AI components
Implement cryptographic signing for model artifacts
Secure training infrastructure with access controls
Maintain model registry access controls
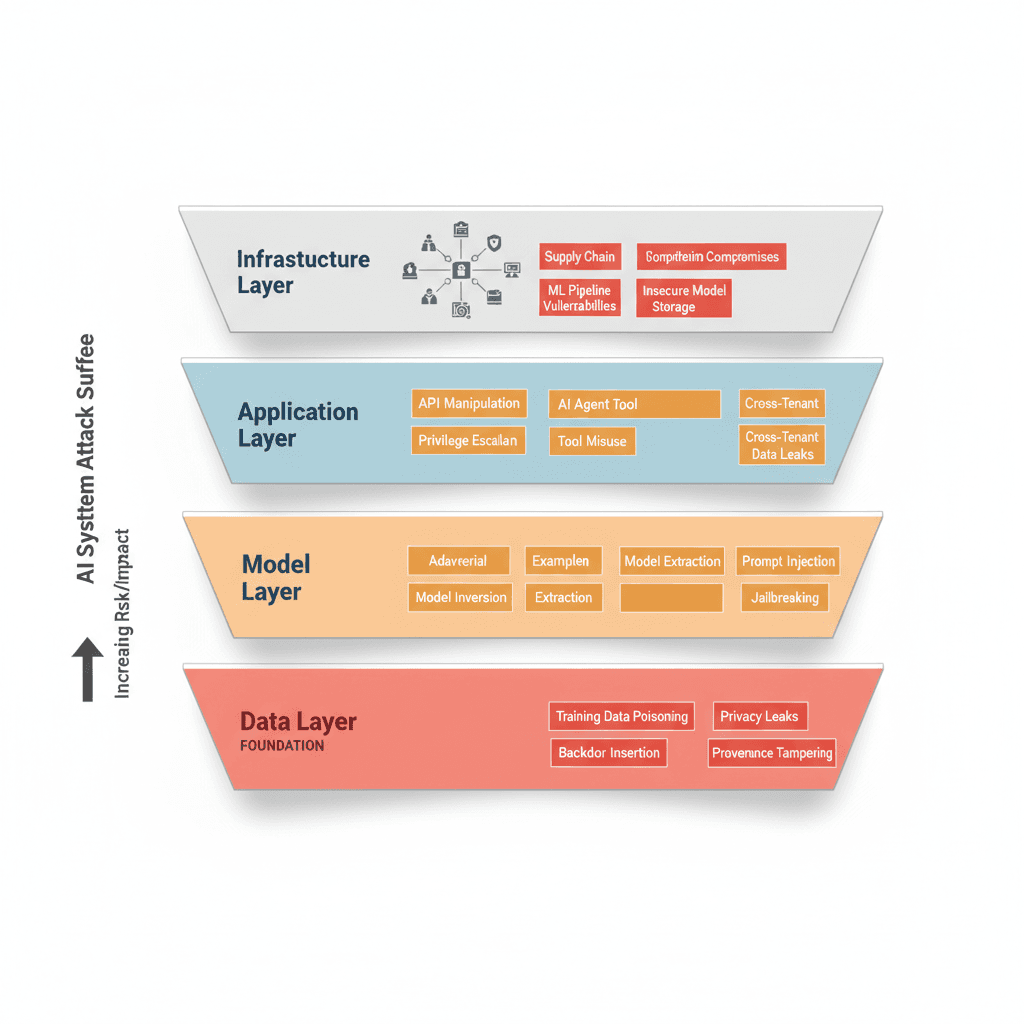
Figure 3: Secure Focus Area - Critical AI System Components and Security Considerations
2.2 Focus Area 2: Defend—Using AI to Strengthen Cybersecurity
This Focus Area represents a shift in perspective: from defending against threats to AI systems, to leveraging AI as a defensive tool. While AI introduces new risks, it also offers defensive capabilities organizations have never had before.
Modern cybersecurity at scale has become fundamentally an information problem. Security teams drown in alerts. Network traffic is enormous and mostly legitimate. Anomalies are buried in noise. Human analysts cannot keep pace with the volume. AI fundamentally changes this dynamic.
For decades, cybersecurity has been reactive: an attack occurs, you detect it (eventually), and you respond. AI enables proactive defense. Machine learning models trained on historical threat data, vulnerability disclosures, threat actor behavior, and network activity patterns can identify attack vectors likely to target your specific organization. This does not guarantee perfect prediction—the threat landscape is too dynamic for that. But it represents a fundamental shift from pure reaction to informed anticipation.
Threat actor profiling exemplifies this capability. By analyzing open-source intelligence—public databases, forums, historical attack campaigns—AI can identify which threat actors most likely target your industry, what tactics and techniques they favor, and which vulnerabilities they typically exploit. This enables tailored defenses focused on relevant threats rather than spreading resources across generic controls.
Advanced Threat Detection with UEBA
User and Entity Behavior Analytics (UEBA) powered by machine learning represents one of the most successful applications of AI to cybersecurity. The principle is straightforward: establish behavioral baselines for users and systems, then use machine learning to detect deviations from those baselines that might indicate compromise.
The key advantage over traditional detection methods is that UEBA doesn't rely on knowing attack signatures in advance. It identifies previously unseen threats through anomaly detection. A user logging in from an unusual geographic location at 3 AM, accessing databases they've never touched before, and transferring unusual data volumes looks suspicious to these systems—and appropriately so.
The quantitative results are compelling. Machine learning-based UEBA systems reduce false positives compared to traditional rule-based detection by up to 60%. This matters because alert fatigue is a genuine problem. When analysts face hundreds of daily alerts, many being false positives, fatigue sets in and genuine threats are missed. Better anomaly detection means fewer overall alerts, but higher quality of those alerts. Fewer false positives means analysts spend time on real issues rather than chasing ghosts.
Autonomous Defense at Scale
This is where the conversation becomes genuinely interesting. What if defensive actions did not require human authorization? What if AI agents could recognize attacks and implement defensive responses autonomously, with humans maintaining oversight?
This is increasingly becoming reality. Organizations are experimenting with multi-agent systems where AI agents coordinate to identify attacks and execute defensive actions, checking each other's work to prevent mistakes.
Consider what this enables. When a security alert triggers, an AI agent could:
- Immediately isolate the affected system from the network
- Revoke relevant credentials
- Block suspicious IP addresses
- Begin forensic data collection
- All within minutes rather than hours
Research suggests these autonomous systems can handle 98% of security alerts and reduce threat containment time to under 5 minutes. For comparison, the median time to detect a breach currently stands at 207 days, with containment taking an additional 72 days. The acceleration is dramatic.
However, autonomous systems require meaningful oversight. Organizations cannot simply release these systems without human visibility. High-stakes decisions need human review, confidence thresholds should trigger human escalation, and teams need the ability to override automated decisions. The objective is augmentation of human capabilities, not replacement.
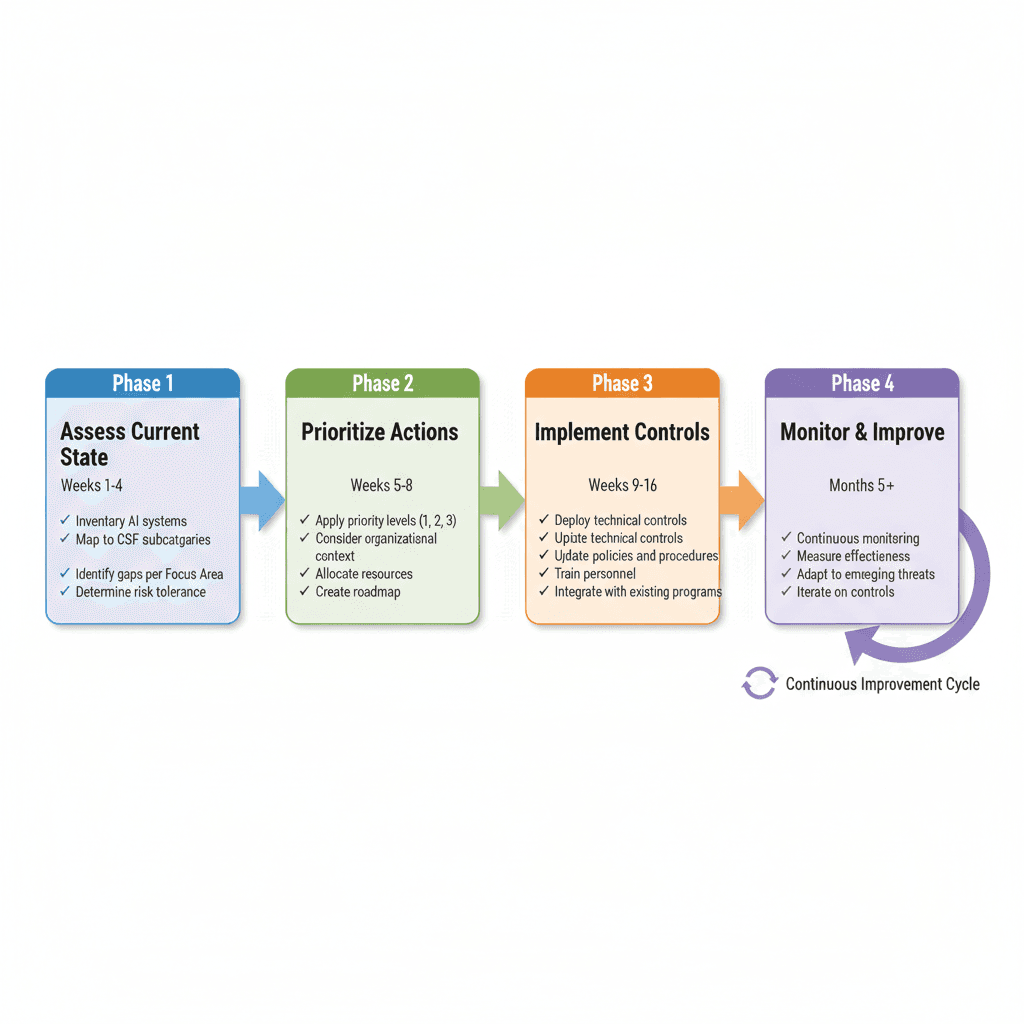
Figure 4: Defend Focus Area - AI-Enabled Cybersecurity Opportunities by Category
2.3 Focus Area 3: Thwart—Defending Against AI-Enhanced Attacks
The uncomfortable reality: the same AI capabilities organizations excitedly deploy defensively? Attackers have them too. In many cases, attackers reached them first. This Focus Area acknowledges that adversaries increasingly leverage AI to enhance attack capabilities, and organizations must prepare.
Sophisticated attacks that previously required expert knowledge and significant resources can now be automated and deployed by less-skilled attackers. Barriers to entry for advanced attacks have dropped dramatically.
AI-Generated Spear Phishing at Scale
Historically, targeted phishing required significant manual effort. An attacker researches targets, crafts convincing messages, and hopes for clicks. Success rates typically ran 3-5%.
Today? AI-generated spear-phishing emails achieve 56% click-through rates—matching expert-crafted scams and outperforming generic phishing by 350%.
How is this possible? The AI automatically builds detailed vulnerability profiles of targets with 88% accuracy by scraping LinkedIn, company websites, job postings, and social media. It understands organizational structure, identifies decision-makers, learns their communication style, and crafts personalized messages referencing specific details from targets' personal and professional lives.
The investment from attackers drops from hours to minutes. The effectiveness increases dramatically. An organization might receive thousands of personalized, contextually accurate phishing emails that exploit knowledge specific to each recipient. A CFO receives messages referencing recent company acquisitions and using terminology from similar transactions. A network administrator receives technical-sounding messages referencing infrastructure details. A recruiter receives messages from apparent job candidates with résumés tailored to open positions.
This represents a qualitative difference from traditional phishing. The barrier to deploying sophisticated social engineering has dropped from "requires skilled attacker" to "available to anyone with API access."
Deepfakes and Voice Cloning
Generative AI has enabled something genuinely concerning: attackers can now create convincing video and audio impersonating executives and colleagues.
Voice cloning technology can clone voices with minimal sample audio—sometimes just 3-5 seconds of real speech. Video deepfakes are increasingly difficult to distinguish from authentic content. LLMs generate perfectly credible text in any style or tone. The tools are freely or cheaply available. The technical barrier is low.
This has real financial consequences. In Hong Kong, attackers used deepfaked video and audio to impersonate a company CFO during a multi-person video call, resulting in a $25 million fraudulent transfer. In the UK, cybercriminals deepfaked a CEO's voice to authorize a €220,000 transfer. These attacks succeed because they exploit fundamental human trust in familiar voices and faces.
The scale is growing. Deepfake spear-phishing attacks have surged over 1,000% in the past decade. This is not a future concern—it is a present threat organizations must address now.
AI-Generated Malware and Autonomous Attack Orchestration
Attackers leverage AI to generate malware that defeats traditional detection systems. Polymorphic malware—malware that changes its code structure with each iteration while maintaining functionality—can now be generated at scale. It executes from computer memory rather than disk, making detection harder. It uses novel file types and encodings to hide instructions. It employs obfuscation techniques that defeat static analysis.
Real examples demonstrate this is happening now. LameHug malware, identified in July 2025, uses the Hugging Face API to interact with large language models to generate malicious commands in multiple languages for Windows systems. The ScopeCreep campaign developed Windows malware toolkits with privilege escalation and obfuscation using AI techniques.
Most concerning: autonomous AI agents can orchestrate multi-stage attacks without human involvement. Research shows AI agents increasingly operate common cybersecurity tools autonomously—network scanners, password crackers, exploitation frameworks, binary analysis suites.
An AI agent can conduct reconnaissance, identify vulnerabilities, exploit them, harvest credentials, move laterally through networks, and exfiltrate data, all with minimal human direction. Where human attackers might take days or weeks to progress through attack sequences—allowing defense teams time to detect and respond—AI agents might complete the entire kill chain in hours or minutes.
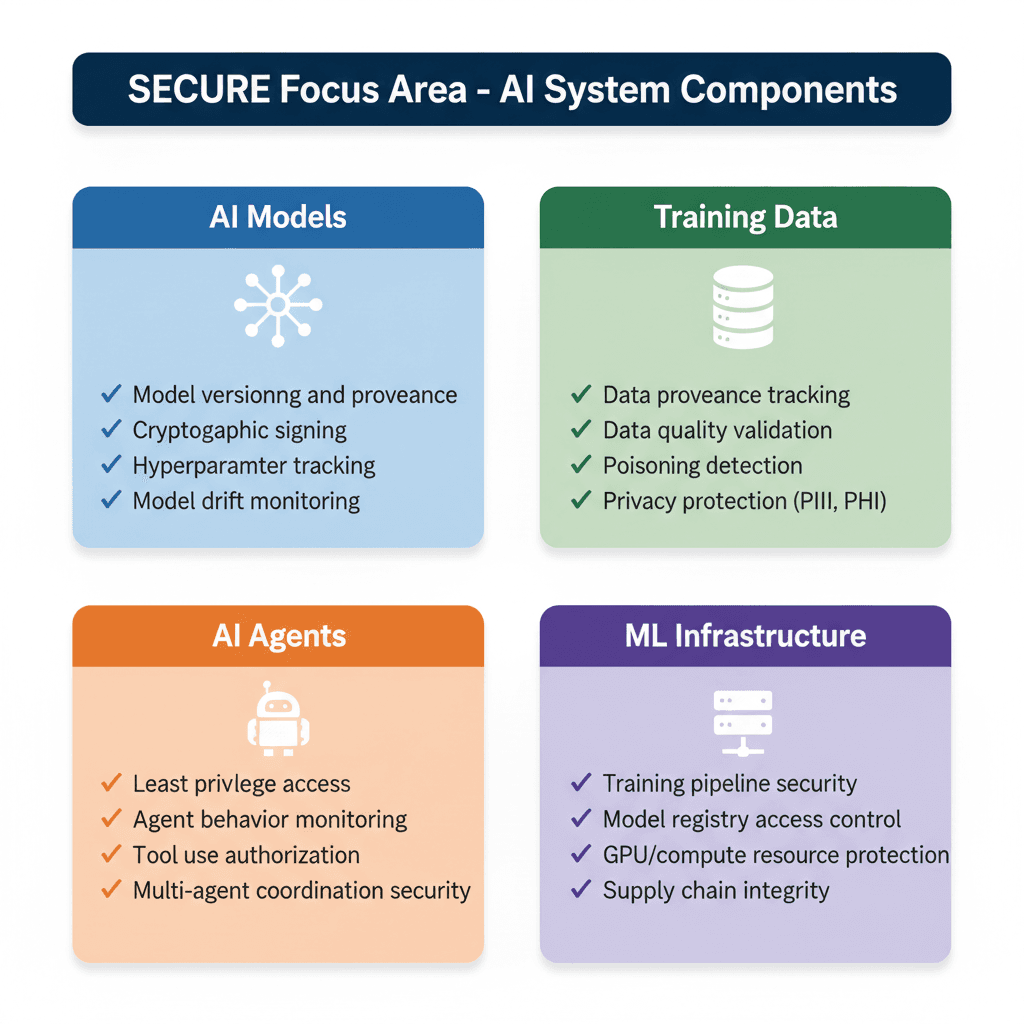
Figure 5: Thwart Focus Area - Taxonomy of AI-Enabled Cyber Attack Threats
3. Implementation Architecture and Technical Patterns
3.1 Zero Trust Architecture for AI Systems
Organizations serious about AI security need to think about zero trust principles specifically applied to AI systems. Traditional zero trust addresses user and device authentication. AI systems introduce new considerations.
Continuous verification becomes essential. Unlike traditional systems where authentication occurs once at session initiation, AI systems—particularly autonomous agents—operate over extended periods. You need continuous verification of their identity and authority throughout their operations.
Least privilege access for AI agents means agents receive only minimum permissions necessary for designated functions. This should not be static—implement just-in-time provisioning where permissions are granted dynamically for specific tasks and automatically revoked upon completion.
Micro-segmentation is critical. AI workloads should be isolated in network segments with strict inter-segment access controls. A compromised AI system should not have clear paths to pivot into other organizational resources.
Modern Identity and Access Management (IAM) systems must support AI-specific entities:
Service accounts for ML training pipelines
API keys for model inference endpoints
Agent identities with delegated permissions
Model-to-model authentication for chained AI systems
Finally, behavioral analytics integration allows zero trust systems to leverage UEBA to establish behavioral baselines for AI systems themselves, detecting anomalies like AI models querying unusual data sources, calling APIs in unexpected sequences, or demonstrating behaviors inconsistent with their defined objectives.
3.2 MLOps Security: Integrating Security Throughout the ML Pipeline
For organizations building or heavily customizing AI systems, security must be integrated throughout machine learning operations (MLOps), not bolted on at the end. A five-stage security framework aligns with typical ML lifecycle stages:
Stage 1: Data Ingestion and Preparation
Before data reaches model training, implement validation processes:
Verify data provenance and integrity before ingestion
Scan for poisoning attempts using anomaly detection
Implement data sanitization and filtering
Maintain versioned datasets with cryptographic hashes
Stage 2: Model Training and Development
Training should happen in isolated, monitored environments:
Implement access controls for training infrastructure
Log all hyperparameter configurations and model checkpoints
Scan trained models for embedded malware or backdoors
Implement change tracking for all training-related configurations
Stage 3: Model Validation and Testing
Before deployment, models should undergo rigorous testing:
Conduct adversarial testing specifically designed to find vulnerabilities
Implement red-teaming exercises targeting model security
Validate model outputs against safety benchmarks
Test for bias, fairness, and robustness in edge cases
Stage 4: Deployment and Inference
Production deployment requires security-focused controls:
Deploy models in secure runtime environments
Verify model integrity before loading and running
Monitor inference requests for adversarial patterns
Implement rate limiting and input validation
Log all inputs, outputs, and model decisions for auditability
Stage 5: Monitoring and Maintenance
Post-deployment monitoring must be continuous:
Monitor for model drift and performance degradation
Implement automated alerting for anomalous behavior
Maintain rollback capabilities to previous model versions
Regularly retrain models to address drift and emerging threats
This entire process should integrate into CI/CD pipelines with security testing gates that prevent deployment of models failing security criteria.
3.3 Implementation Workflow Overview

Figure 6: Four-Phase Implementation Roadmap for Cyber AI Profile Adoption
Most organizations will not implement everything simultaneously. A phased approach proves more practical. The NIST framework suggests a progression through four distinct phases:
Phase 1: Assess and Baseline (Weeks 1-4)
- Inventory all AI systems across the organization
- Classify by criticality, data sensitivity, and decision-making autonomy
- Conduct risk assessment for each Focus Area
- Map current capabilities to Cyber AI Profile subcategories
- Identify critical gaps using the priority framework
Phase 2: Prioritize and Plan (Weeks 5-8)
- Determine priorities considering organizational context and risk tolerance
- Develop business cases for high-priority initiatives
- Allocate resources and assign ownership
- Establish timelines and success metrics
Phase 3: Implement Controls (Weeks 9-16)
- Deploy technical controls for AI-specific security
- Update policies and procedures
- Conduct personnel training
- Integrate with existing security programs
Phase 4: Monitor and Improve (Months 5+)
- Continuous monitoring of implementation progress
- Measurement of control effectiveness
- Adaptation to emerging threats
- Iteration based on operational feedback
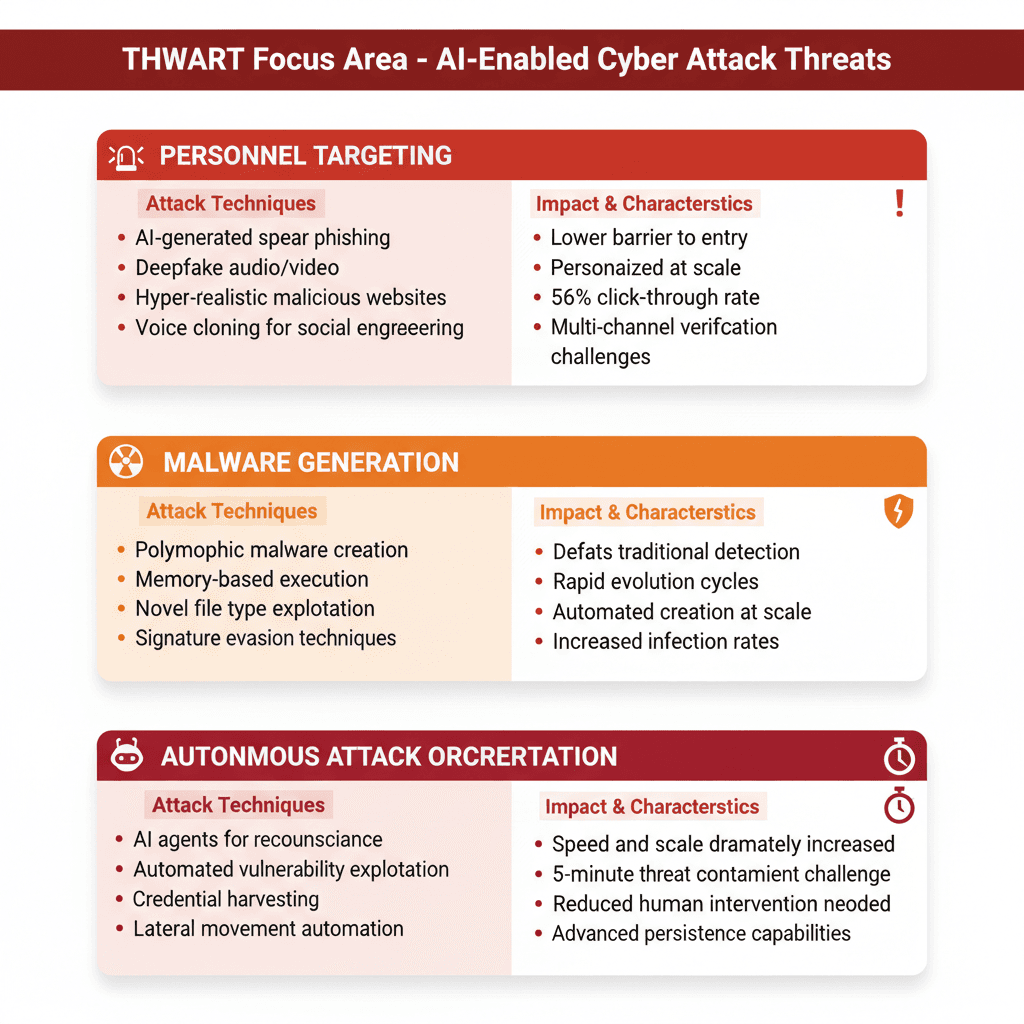
Figure 7: Priority Framework - Three-Tier Implementation Hierarchy
4. CSF 2.0 Integration and Governance
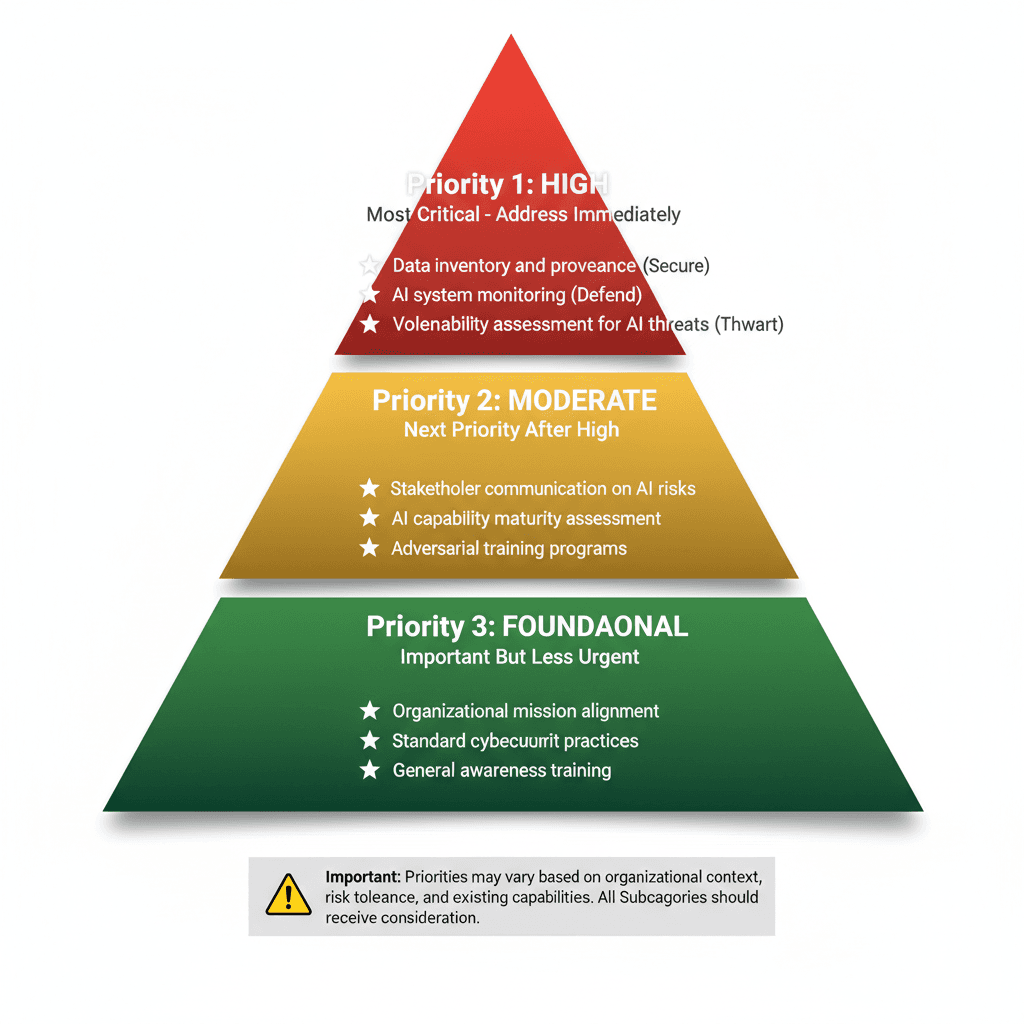
Figure 8: NIST CSF 2.0 Core Functions - Framework Structure Overview
The Cyber AI Profile maps directly to the six functions of NIST CSF 2.0, enabling organizations to integrate AI considerations into existing cybersecurity programs without creating parallel governance structures.
The GOVERN function establishes organizational context including AI adoption strategies and stakeholder expectations. Organizations should address:
Organizational context including AI adoption strategies
Risk management strategies incorporating AI-specific threats
Policies governing AI development, deployment, and monitoring
Supply chain risk management for AI components and datasets
The IDENTIFY function encompasses organizational understanding of cybersecurity risks specific to AI systems. The PROTECT function addresses safeguards to ensure service delivery despite AI-enabled threats. DETECT focuses on identifying AI-enabled attacks and anomalous model behavior. RESPOND provides processes for reacting to AI security incidents. RECOVER enables restoration of capabilities after AI-related compromises.
This alignment with CSF 2.0 provides significant practical benefits. Organizations already familiar with CSF can extend existing programs rather than learning entirely new frameworks. Existing governance structures, risk assessment processes, and compliance mechanisms can incorporate AI-specific considerations incrementally. This reduces organizational disruption while enabling systematic security improvements.
5. Practical Implementation: Real-World Scenarios
5.1 Enterprise AI Security Assessment Workflow
AI System Discovery
An enterprise typically discovers it has more AI systems than originally recognized. There is the customer service chatbot deployed by the business unit. There are recommendation engines in the e-commerce platform. Teams use ChatGPT for document analysis. ML models power fraud detection in payments. Predictive maintenance systems run in manufacturing. Each represents both opportunity and risk.
Many organizations find shadow AI systems: applications deployed without IT involvement, personal tools adopted by employees, legacy systems with embedded ML components. The first step requires comprehensive discovery and classification.
Risk Assessment by Focus Area
For each discovered system, the organization evaluates:
Secure: Is data provenance tracked? Are models signed? Is the supply chain vetted? What are the implications if this system is compromised?
Defend: Are we using AI to enhance security monitoring? Are we missing opportunities to leverage AI for better threat detection?
Thwart: Are our defenses adequate against AI-generated phishing? Do we have resilience against polymorphic malware? Can we detect autonomous agent activities?
This assessment typically reveals significant gaps. Many organizations discover they have no comprehensive tracking of training data provenance, no cryptographic signing of deployed models, limited use of AI in security operations, and no specific defenses against AI-enabled attacks.
Gap Prioritization and Roadmap Development
Using the three-tier priority framework, organizations prioritize remediation:
High Priority initiatives typically include:
- Implementing data provenance tracking for critical AI systems
- Deploying anomaly detection in security monitoring
- Conducting employee training on deepfakes and AI-generated attacks
Moderate Priority initiatives include:
- Model signing and cryptographic verification
- Establishing AI-focused red-teaming programs
- Implementing behavioral monitoring for AI agents
Foundational Priority initiatives include:
- General AI security awareness programs
- Governance documentation and policy development
- Supply chain assessment and vendor management
This prioritization enables organizations to allocate resources toward highest-impact improvements while maintaining realistic implementation timelines.
5.2 AI Security Incident Response
Detection and Triage
When an incident occurs involving AI systems, response differs fundamentally from traditional IT incidents because AI systems have unique characteristics:
A fraud detection model suddenly stops flagging fraudulent transactions it previously identified. Analysts notice model performance degradation beyond expected variations. The system gets flagged as potentially compromised.
Initial investigation determines whether this represents:
- Data poisoning in the training dataset
- Model tampering or direct corruption
- Supply chain compromise of model dependencies
- Infrastructure compromise of training or inference systems
Investigation and Root Cause Analysis
Initial investigation pulls:
- Model checkpoint history to identify when performance changed
- Training data logs to identify potential poisoning
- Access logs to determine unauthorized modifications
- Inference logs to spot anomalous prediction patterns
Root cause analysis determines:
- Whether compromise was data poisoning, model tampering, or infrastructure attack
- When compromise occurred and how long it persisted
- What information might be leaked if this was targeted attack
- Scope of impact on downstream systems or users
Response and Recovery
Response activities include:
- Isolating affected systems to prevent further damage
- If poisoning suspected, retraining on clean historical data
- If tampering suspected, restoring from cryptographically verified backups
- Implementing additional monitoring to prevent recurrence
- Updating detection rules for similar attack patterns
Post-incident analysis includes:
- Comprehensive forensic investigation
- Update to threat intelligence
- Sharing findings with relevant organizational teams
- Assessment of customer or regulator notification requirements
6. Key Considerations and Limitations
6.1 Addressing Overreliance on AI-Based Defenses
While AI offers tremendous defensive advantages, organizations must recognize genuine limitations. Overreliance represents a critical risk. When AI systems make decisions or flag threats, analysts can develop bias toward trusting those outputs without appropriate skepticism. Sophisticated attackers exploit this dynamic by crafting attacks specifically designed to pass AI-based detection, knowing humans are predisposed to trust AI outputs.
Organizations must implement human-in-the-loop oversight where humans understand business context, can override machine decisions when needed, and maintain ultimate accountability for security outcomes. Confidence thresholds should trigger human review for sensitive decisions. Tools should present reasoning alongside predictions to enable informed human judgment.
6.2 Managing False Positives and False Negatives
Despite improvements, machine learning systems still generate false positives (flagging legitimate activity as suspicious) and false negatives (missing genuine threats). Alert fatigue from excessive false positives causes analysts to miss real threats. Organizations must acknowledge these limitations and design response processes accordingly.
Implementing dynamic multi-layer risk scoring that assigns risk values rather than flagging every anomaly enables security teams to prioritize high-risk activity. Regularly tuning thresholds based on operational experience improves accuracy over time. Measuring and reporting both false positive and false negative rates maintains realistic expectations about system capabilities.
6.3 Securing AI Systems That Defend Your Environment
AI systems themselves can be attack targets. If attackers poison the data that trains your defensive AI, manipulate it into missing real threats, or trick it into generating false alerts that waste resources, they have compromised your defense. Organizations must apply the same rigorous security practices to defensive AI systems as they apply to any other critical infrastructure.
This includes data provenance tracking for defensive AI training data, cryptographic integrity verification for defensive models, access controls for defensive AI development infrastructure, and regular security assessment of defensive systems.
7. Future Research Directions and Emerging Challenges
The Cyber AI Profile represents an important starting point in a longer journey. Several areas require continued research and development:
Formal Verification for AI Systems: Developing mathematical techniques to prove AI system properties and constraints, providing stronger security guarantees than empirical testing alone can offer.
Automated Adversarial Testing: Creating AI-driven red-teaming systems that continuously probe for vulnerabilities, turning the competitive arms race into an advantage for defenders.
Explainable AI for Security: Advancing interpretability techniques that allow security teams to understand AI decision-making, improving incident investigation and enabling appropriate trust in AI systems.
Standardized AI Security Metrics: Establishing industry-standard metrics for measuring AI system security posture, enabling benchmarking and compliance verification across organizations.
AI Safety and Security Convergence: Bridging the gap between AI safety research (focused on alignment and robustness) and cybersecurity (focused on adversarial threats), creating integrated frameworks addressing both dimensions.
Supply Chain Security Standards: As the ML supply chain matures, developing clearer standards for model provenance, data tracking, and supply chain integrity verification.
8. Conclusion and Recommendations
The release of the NIST Cyber AI Profile represents something significant: the security and AI communities getting serious about addressing a critical gap. We have known for some time that AI systems have unique security challenges. Now we have a structured framework for discussing and addressing them systematically.
For academic researchers, this framework opens numerous avenues for investigation: How do we formally verify AI system security? How do we detect data poisoning more effectively? What detection methods work best against AI-generated malware? How can red-teaming be automated and scaled? How can we build explainability into security-critical AI systems?
For security practitioners, the framework provides structure for integrating AI security into existing programs. It acknowledges both the risks AI introduces and the opportunities AI provides for defense. It offers prioritization guidance rooted in operational experience and stakeholder input.
For AI developers and data scientists, the framework provides clarity about security requirements throughout the ML lifecycle. It normalizes security considerations as integral to responsible AI development rather than afterthoughts or compliance burdens.
Most importantly, NIST is actively seeking feedback. The preliminary draft remains open for comment until January 30, 2026. If you work with AI systems, security, or the intersection of the two, engagement in this process matters. Your perspectives will shape the final framework that organizations adopt.
Recommendations:
For Organizations:
1. Conduct comprehensive AI system inventories
2. Assess current capabilities against the three Focus Areas
3. Develop prioritized implementation roadmaps
4. Integrate AI security into existing governance structures
5. Invest in both technical controls and personnel training
For Security Teams:
1. Build AI security expertise within your organization
2. Establish red-teaming practices specific to AI systems
3. Develop incident response procedures for AI-specific compromises
4. Monitor emerging AI security threats
5. Engage with the AI security community
For AI Teams:
1. Integrate security into ML development processes
2. Implement data provenance tracking
3. Cryptographically sign and verify models
4. Conduct regular security assessments
5. Maintain audit trails for all development activities
The question is not whether organizations will integrate AI more deeply into operations. That is inevitable. The question is whether they will do it securely. The Cyber AI Profile provides a roadmap. Now comes the harder work: actually implementing it.
References
[1] NIST IR 8596 iprd - Cybersecurity Framework Profile for Artificial Intelligence
[2] NIST CSF 2.0 Framework Update, 2024
[3] Adversarial AI: Understanding and Mitigating the Threat, Sysdig, 2023
[4] The Rise of AI-Generated Attacks: Why UEBA is the Best Defense, Exabeam, 2025
[5] NIST CSF Categories & Subcategories: Complete Guide, IPKeys, 2025
[6] Understanding the AI Attack Surface, Silobreaker, 2025
[7] Top 5 User & Entity Behavior Analytics (UEBA) Tools, Stellar Cyber, 2025
[8] NIST CSF Categories: Description, Examples, and Best Practices, Device42, 2024
[9] What Are Adversarial AI Attacks on Machine Learning? Palo Alto Networks, 2019
[10] AI-Powered Security Monitoring, Seceon, 2025
[11] NIST CSF 2.0: A Brief Introduction, Kudelski Security, 2024
[15] Combating the Threat of Adversarial Machine Learning, ISACA, 2025
[22] What is AI Data Poisoning? Upwind, 2025
[23] Generative AI Phishing: A Guide for Security Leaders, Adaptive Security, 2025
[24] What is Agentic AI? Understanding Autonomous Intelligence, Qualys, 2024
[25] The AI Supply Chain Security Imperative: 6 Critical Controls, Coalition for Secure AI, 2025
[26] Deepfake Attacks & AI-Generated Phishing: 2025 Statistics, ZeroThreat AI, 2025
[27] What is Agentic AI Cybersecurity? Gurucul, 2025
[28] LLM03:2025 Supply Chain - OWASP Gen AI Security Project, 2025
[29] Phishing 3.0: AI and Deepfake-Driven Social Engineering Attacks, CM Alliance, 2025
[31] Introduction to Data Poisoning: A 2025 Perspective, Lakera AI, 2025
[34] AI Supply Chain Security: Why It's Becoming Harder to Ignore, Wiz, 2025
[36] Transforming Cybersecurity with Agentic AI, Multiple Sources, 2025
[37] Google Guidance on AI Supply Chain Security, Google Cloud, 2024
[42] AI Security Testing: Protecting Models and Agents, Obsidian Security, 2025
[43] Zero Trust Identity And Access Management, Cerby, 2024
[45] Red Teaming Playbook: Model Safety Testing Framework, CleverX, 2025
[46] Zero Trust & Identity and Access Management, Cloud Security Alliance, 2024
[48] What is Red Teaming in AI? Lasso Security, 2025
[50] Understanding the NIST AI RMF Framework, LogicGate, 2025
[51] LLM Red-Teaming and Adversarial Testing, Evidently AI, 2024
[52] Zero Trust Security & Access Management, CloudEagle, 2025
[54] Towards Secure MLOps: Surveying Attacks and Mitigation, IEEE/ArXiv, 2024
[59] Artificial Intelligence Risk Management Framework (AI RMF 1.0), NIST, 2023